Statistics
Dr. Larry Genalo
02-24-2013
Statistics
Statistics
Variation

Variation
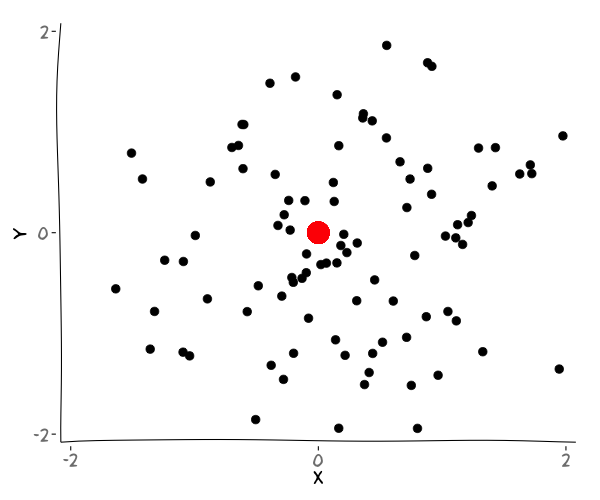
Variation

Variation
Alternative Deviation Equation
Example
Example
Example
Example
Example
Example 2

Frequency Distribution
This can lead to a Continuous Distribution such as:

This is an example of a theoretical distribution called the Normal Distribution or a “Bell-Shaped” curve. This is used when grading “on a curve” and also applies to many natural phenomena.
Curve Fitting
Curve Fitting Problem
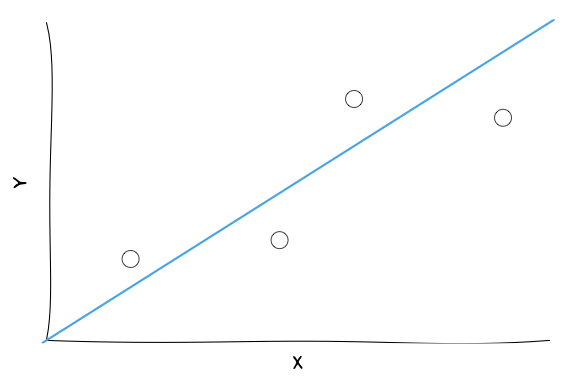
The problem:
We know that a straight line has the form \( Y=mX+b \)
What values of \( m \) and \( b \) are the “best”?
Curve Fitting Solution

The red lines indicate how far the fitted line is from the true data points.
Curve Fitting Solution

- \( (X_p, Y_p) \) is the real data
- \( {Y'}_p = mX_p+b \) gives us the predicted Y value for \( X_p \)
- The distance “missed by”
- \( Y_p-{Y'}_p= Y_p - (mX_p + b) \)
Curve Fitting Solution
Curve Fitting Solution
Common Concern
Given ANY set of data points, we can find \( m \) and \( b \). Is it always a good idea to do this?
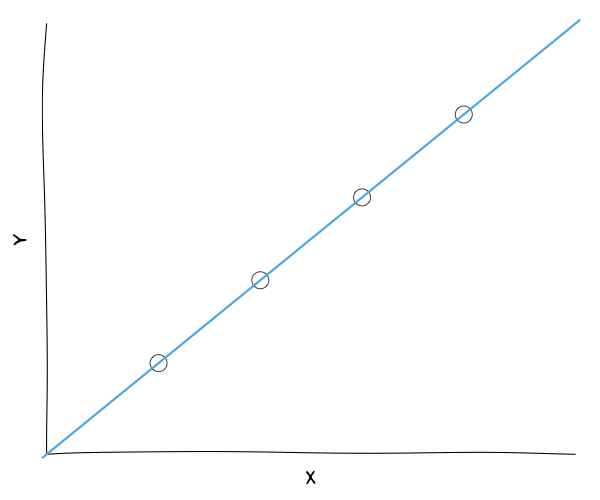
Common Concern
Given ANY set of data points, we can find \( m \) and \( b \). Is it always a good idea to do this?
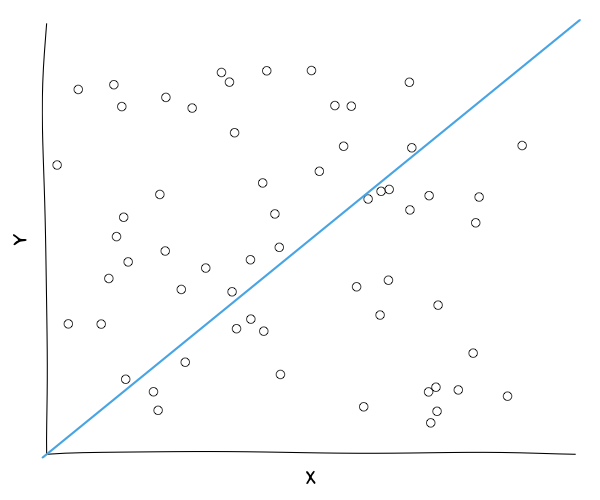
Correlation Coefficient
Correlation Coefficient
Alternative R
Suggestions
Nonlinear Graphs
“Patterned” data not following a straight line?
Model with a curved line
Transform to a straight line model
